

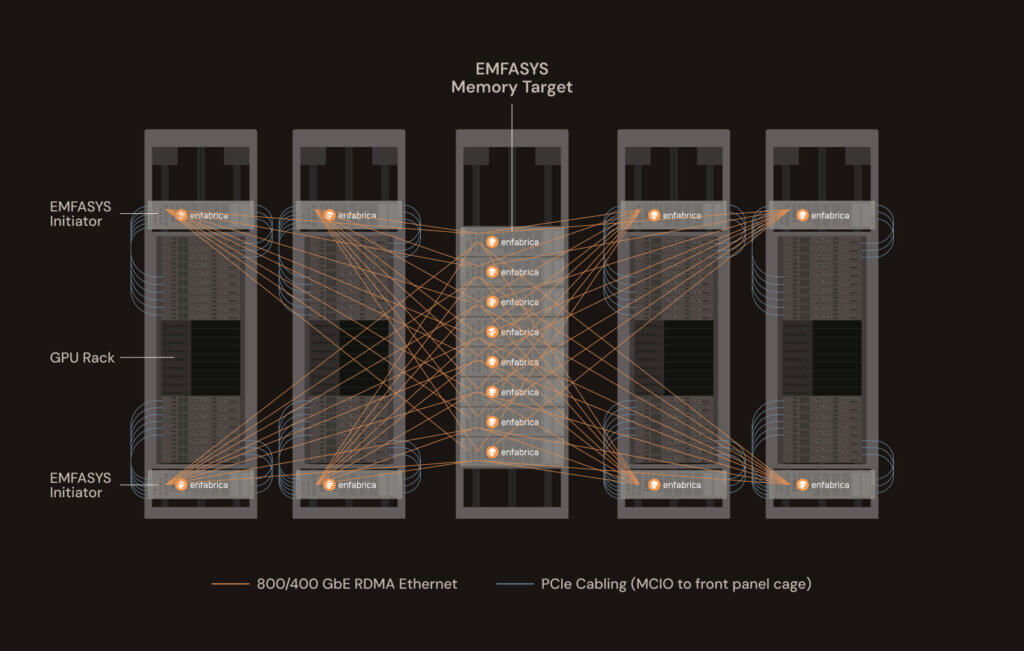
Enfabrica, a start-up based in Mountain View, California, introduced its Elastic Memory Fabric System (EMFASYS), a new hardware and software platform designed to solve memory bottlenecks in large-scale AI inference workloads. EMFASYS combines Remote Direct Memory Access (RDMA) Ethernet networking with ComputeExpressLink (CXL) DDR5 memory to provide pooled, rack-scale memory accessible by any GPU server over standard Ethernet ports.
The system delivers multi-800GB/s read-write throughput and up to 18 TB of pooled DRAM per node, allowing cloud providers to offload GPU-attached HBM into a shared memory pool. According to Enfabrica, this enables up to 50% lower cost per token per user in inference workloads, while maximizing GPU utilization and reducing stranded compute resources.
At the core of EMFASYS is Enfabrica’s 3.2 Tbps Accelerated Compute Fabric SuperNIC (ACF-S). Unlike traditional NICs, ACF-S integrates high-throughput GPU networking with CXL memory aggregation, connecting up to 144 DDR5 channels and enabling massively parallel RDMA-over-Ethernet transfers. A caching hierarchy, managed by Enfabrica’s software stack based on Infiniband Verbs, hides memory transfer latency within inference pipelines, maintaining microsecond access times.
Enfabrica is positioning EMFASYS as an “Ethernet memory controller” for AI data centers, allowing operators to decouple memory scaling from GPU scaling. The solution is currently sampling and piloting with AI infrastructure customers.
Key Features
- 3.2 Tbps ACF-S SuperNIC connects GPU servers to pooled memory over 400/800 GbE
- Up to 18 TB DDR5 DRAM per node shared across workloads via CXL
- Multi-800 GB/s throughput with microsecond-level read latency
- 100x lower latency vs. flash-based inference storage
- Software-managed caching hierarchy to optimize inference pipelines
“AI Inference has a memory bandwidth-scaling problem and a memory margin-stacking problem. As inference gets more agentic versus conversational, more retentive versus forgetful, the current ways of scaling memory access won’t hold. We built EMFASYS to create an elastic, rack-scale AI memory fabric and solve these challenges in a way that hasn’t been done before.” — Rochan Sankar, CEO of Enfabrica
🌐 Why it Matters: Generative and agent-driven AI workloads are increasingly memory-bound rather than compute-bound, requiring far greater context retention and throughput than earlier LLM deployments. Traditional scaling approaches rely on adding GPU HBM or CPU DRAM within each server, driving up costs and limiting efficiency.
By pooling commodity DRAM over Ethernet and making it transparently available to GPUs at low latency, Enfabrica enables AI operators to optimize both performance and economics. The EMFASYS system addresses the twin challenges of memory bandwidth scaling and token economics, making it possible to deliver higher user/agent counts and larger-context workloads at significantly lower infrastructure cost.
🌐 Company Overview: Enfabrica, a semiconductor and cloud-infrastructure startup founded in 2019 and headquartered in Mountain View, California, is tackling I/O and memory bottlenecks in large-scale AI and accelerated computing systems. By developing unified fabrics, Enfabrica enhances resiliency, scale, and performance for next-generation AI infrastructure.
Its flagship product, the Accelerated Compute Fabric SuperNIC (ACF-S), is a high-performance 8 Tbps networking silicon designed to interconnect GPUs, CPUs, memory, and accelerators seamlessly. This enables multi-terabit data movement with low latency, supporting dynamic load balancing and fault tolerance in AI clusters.


ACF-S: The SuperNIC Powerhouse
The ACF-S is a “fabric switch on a chip,” integrating Ethernet switching, RDMA, and CXL protocols for unified interconnects. Key specifications include:
- Bandwidth: 8 Tbps aggregate throughput, with specific configurations supporting up to 3.2 Tbps per RDMA pipe.
- Use Cases: Optimizes AI cluster scaling, reduces I/O bottlenecks, and supports large language model (LLM) inference at hyperscale.
- Performance: Delivers up to 2x faster AI job completion, 50% lower token costs for inference, and enhanced resiliency.
- Availability: Production began in 2025, with deployments underway. Showcased at Hot Chips 2024 as the “world’s fastest GPU NIC chip.”
The ACF-S supports Ethernet speeds of 400/800 Gbps and up to 18 TB of CXL-attached DDR5 DRAM per node, making it a cornerstone of modern AI infrastructure.
Leadership
Enfabrica’s leadership brings deep expertise in networking and systems architecture:
- Rochan Sankar, Co-Founder & CEO: Former head of engineering at Broadcom’s data-center Ethernet switching group, with degrees in Electrical Engineering (University of Toronto) and an MBA (Wharton).
- Shrijeet Mukherjee, Co-Founder & Chief Development Officer: Architected platforms at Google, Cumulus Networks, Cisco, and SGI, holding numerous patents in system architecture.
Funding and Investors
Enfabrica has raised approximately $260 million in venture capital:
- Series B (September 2023): $125 million, led by Atreides Management with participation from Nvidia.
- Series C (November 2024): $115 million, led by Spark Capital, with investments from Arm Holdings, Cisco Investments, Samsung Catalyst Fund, Maverick Silicon, VentureTech Alliance, Sutter Hill Ventures, Liberty Global Ventures, and Valor Equity Partners.