


At this week’s Hot Chips 2025 at Stanford University, AMD outlined the native AI architecture of its Instinct MI350 Series GPUs and platforms, emphasizing advances in memory bandwidth, compute throughput, and scalability for large AI models. The MI350 family includes two offerings: the MI350X (1.0 kW TDP) and MI355X (1.4 kW TDP), both featuring 288 GB of HBM3E memory with 8 TBps bandwidth and built with 185 billion transistors using AMD’s 3D stacking approach.
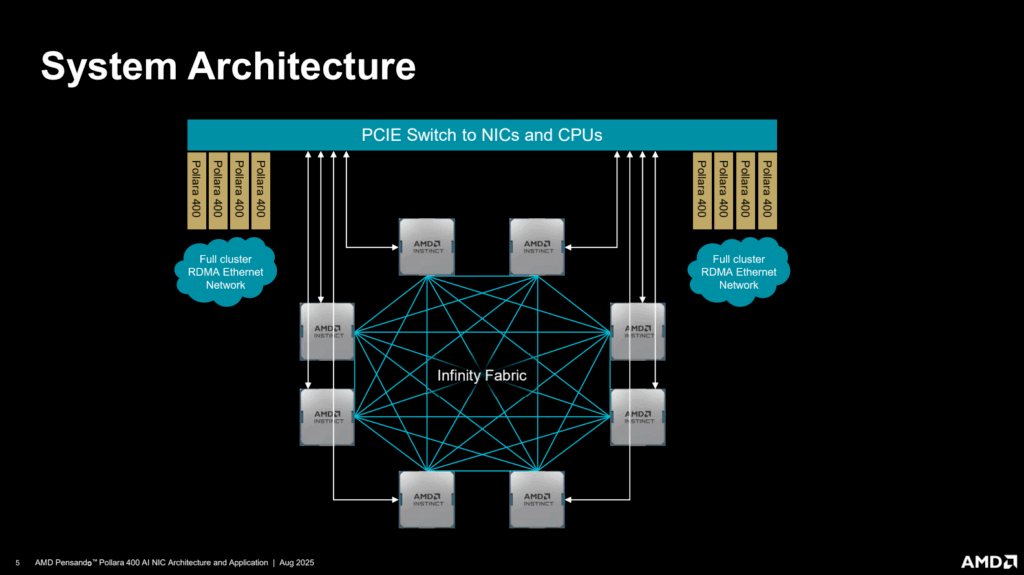
The architecture employs two base dies built on TSMC 6nm and eight Accelerator Complex Dies (XCDs) built on TSMC 3nm. Infinity Fabric has been redesigned to deliver 5.5 TBps of interconnect between dies, along with seven Gen4 links for 1,075 GBps aggregate GPU-to-GPU bandwidth. Each MI350 package contains 256 CDNA4 compute units, doubling math throughput for key AI data types and adding support for MXFP4 and MXFP6. Sparse instructions double throughput further.
On the platform side, MI350 supports both air-cooled and liquid-cooled Open Accelerator Modules (OAMs) designed for Open Compute Project (OCP) racks. Eight GPUs per baseboard form a fully interconnected topology with over 1 TBps of aggregate GPU-to-GPU bandwidth. Hyperscale racks scale up to 128 liquid-cooled GPUs, delivering 2.6 exaflops of FP4 compute and 36 TB of HBM3E memory, while enterprise racks support up to 64 GPUs in air-cooled configurations. AMD is also delivering fully co-engineered solutions with EPYC CPUs, Instinct GPUs, and its own networking, supported by ROCm 7 software with Kubernetes and Slurm integration.
- 288 GB HBM3E memory at 8 TBps bandwidth per GPU
- 2 base dies (TSMC 6nm) + 8 compute dies (TSMC 3nm) + 185B transistors
- Infinity Fabric redesign: 5.5 TBps die-to-die + 1,075 GBps GPU scale-up
- 256 CDNA4 compute units per GPU, with MXFP4/MXFP6 support
- Inference: up to 3x MI300X, 1.3x more tokens/sec than NVIDIA B200
- Training: up to 3.5x higher pre-training throughput vs MI300
- Open Accelerator Module (OAM) form factors: air-cooled (MI350X) and liquid-cooled (MI355X)
- Hyperscale rack: 128 GPUs, 2.6 exaflops FP4, 36 TB HBM3E
“With MI350, we’ve taken a major leap forward, delivering three times more performance across a broad range of AI workloads. Our innovation cadence continues with MI400 and beyond,” said AMD.
🌐 Analysis: AMD’s MI350 design underscores its strategy to win in both AI training and inference by scaling memory capacity and bandwidth alongside compute throughput. The introduction of MXFP formats and ROCm 7 improvements are clear moves to reduce cost-per-token versus NVIDIA, while AMD’s integration of CPUs, GPUs, and networking positions it as a full-stack alternative for hyperscalers. With MI400 already on the roadmap for 2026, AMD is signaling a relentless annual cadence to stay competitive with NVIDIA’s Blackwell and future GB200-class systems.
🌐 We’re tracking the latest developments in AI infrastructure. Follow our ongoing coverage at: https://convergedigest.com/category/ai-infrastructure/