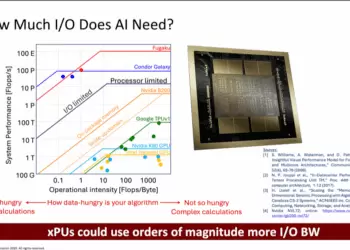
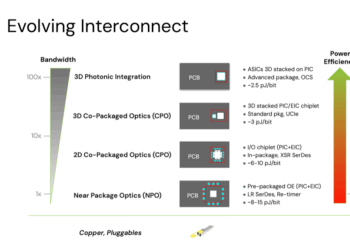
At the Photonic Enabled Cloud Computing (PECC) Summit in Silicon Valley, Drew Alduino, Director of Optical Infrastructure at Meta, addressed the extraordinary pace and complexity of AI infrastructure growth—and the emerging limits of today’s data-center architectures.

Meta, he said, brought online more than a gigawatt of new capacity this year and is investing tens of billions of dollars annually to expand AI training infrastructure. “It’s hard to call this a bubble when every major company is scaling this aggressively,” he observed. “The challenge is how to sustain it.”
Alduino noted Meta’s recently announced 5-gigawatt data-center campus in Louisiana—so large it would cover a significant portion of Manhattan—as an example of the physical scale now required for AI clusters measured in millions of nodes across multiple regions.
From Scale-Out to Scale-Up
AI clusters have evolved from the 24,000-node systems Meta deployed in 2023 to designs exceeding 129,000 GPUs today and soon into multimillion-node, multi-regional fabrics. The architectural questions have shifted from how to scale out across racks to how to scale up within and between racks as power and cooling densities rise.
Meta’s earlier rack generations—A100, H100, and H200—fit within a single physical rack. The newest systems require multi-rack configurations to accommodate cooling and power infrastructure. “We now have compute that spans two racks and needs a six-rack physical solution when you add the cooling,” Alduino said. “Even maintaining a single copper-reach backplane between them becomes a challenge.”
The Limits of Copper
Alduino described how passive electrical backplanes, once considered the simplest and most reliable connection, are becoming bottlenecks as cluster scale and thermal load increase. “How are you going to get more scalable and more reliable than a copper wire?” he asked rhetorically. “That’s the problem we’re facing.”
As scale-up connectivity pushes beyond copper’s reach, optical solutions such as CPO (co-packaged optics), NPO, AEC, and AOC are being evaluated for their performance, reliability, and serviceability trade-offs.
Reliability, Availability, and Serviceability
Alduino framed Meta’s design philosophy around three interdependent goals:
- Reliability – the physical robustness of the components themselves.
- Availability – the system-level resilience and amount of spare capacity needed to absorb inevitable failures.
- Serviceability – the practical ability to detect, access, and replace failed parts without excessive downtime.
“Reliability is what breaks and when; availability is how much capacity you lose when it does; and serviceability is how quickly you can fix it,” he explained.
Different technologies affect these factors in different ways. A pluggable transceiver failure might take down a single link, easily rerouted in the scale-out domain. A CPO failure, by contrast, could disable multiple ports and a larger section of the fabric, raising questions about repair time and spare capacity. “If a CPO port fails, do I lose a switch node?” Alduino asked. “That’s the question we’re trying to answer.”
Meta’s CPO Evaluation
Meta is now testing CPO and pluggable optical systems side by side at scale—roughly 15 million CPO device-hours and two million pluggable-module hours so far—to establish statistically significant reliability data. The results are promising: CPO modules show about a 5× improvement in MTBF over comparable pluggables, with roughly 65 percent lower power consumption and stable operation across temperature.
Still, Alduino cautioned that the most relevant metric is not component failure but link interruption. Firmware, control logic, and transient link resets can have outsized impact on AI training workloads. “After fifteen million device-hours we haven’t seen unserviceable CPO failures,” he said, “but what really matters is whether the link stays up.”
Toward a Data-Driven Decision
Meta’s goal is not simply to validate CPO components but to quantify how failures propagate at the system level—what he called “the blast radius.” The company is building the statistical base needed to understand whether the benefits of integrated optics outweigh the complexity and repair challenges. “The question for us isn’t ‘can the industry build it?’ It’s ‘should we deploy it at scale?’ ”
Alduino closed by emphasizing that reliability and serviceability will ultimately determine how far AI infrastructure can scale. “Power savings help, but the unanswered questions are still reliability, availability, and serviceability,” he said. “If we can make integrated optics truly reliable at data-center scale, that’s how we move forward.”
Key Takeaways
- Meta’s AI infrastructure now exceeds a gigawatt of new capacity and is moving toward multi-million-node, multi-regional clusters.
- Traditional copper backplanes are reaching physical and thermal limits for scale-up connectivity.
- Co-packaged optics (CPO) show promise—roughly 5× higher MTBF and 65 percent lower power—but raise new serviceability questions.
- Reliability, availability, and serviceability (RAS) must be co-optimized as AI fabrics grow.
- Meta is collecting large-scale field data to evaluate CPO versus pluggables before committing to broad deployment.