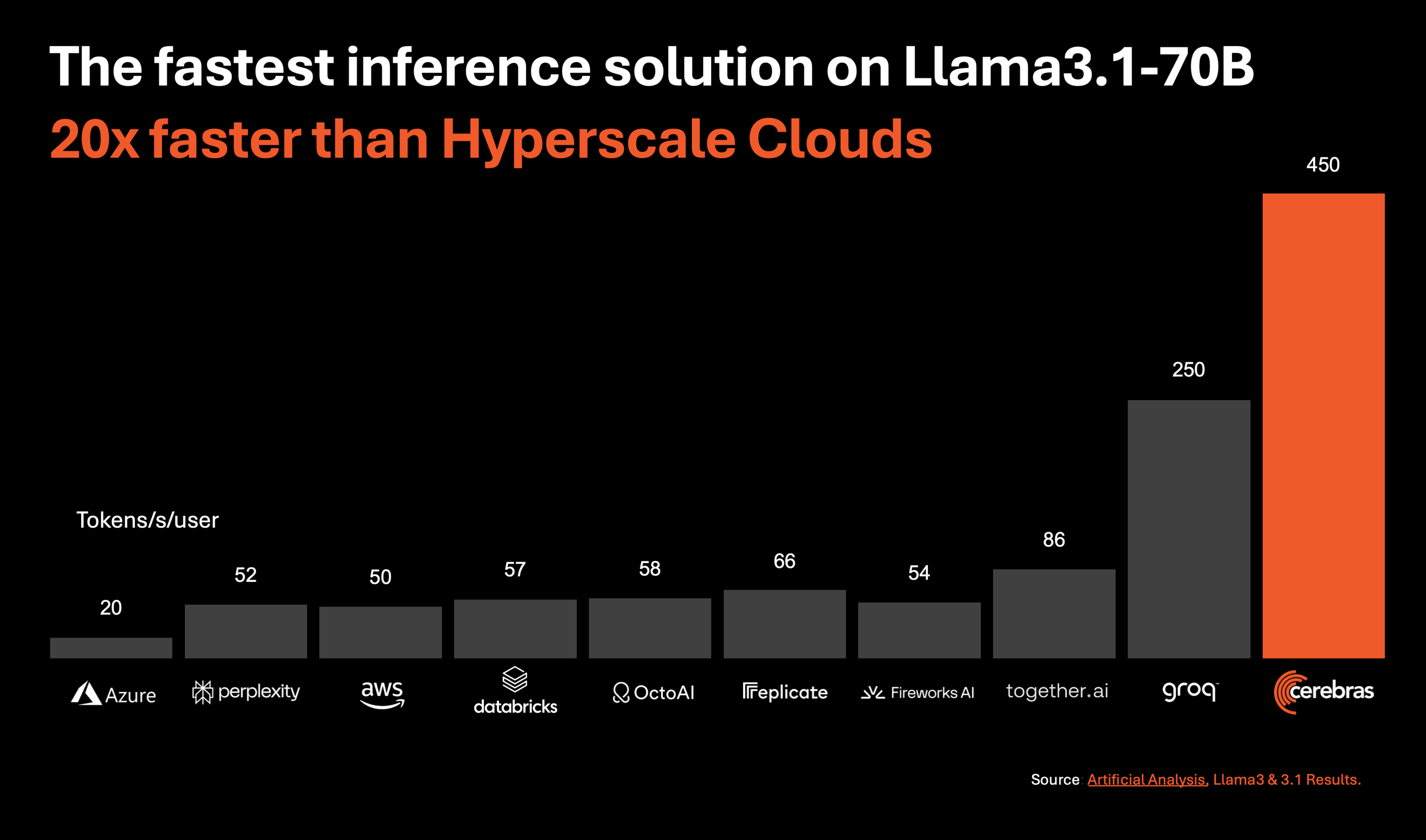
Cerebras Systems introduced a new AI inference solution, claiming it to be the fastest in the world. The Cerebras Inference platform delivers 1,800 tokens per second for the Llama 3.1 8B model and 450 tokens per second for the Llama 3.1 70B model, outperforming NVIDIA GPU-based solutions by 20 times in hyperscale cloud environments. The solution is priced competitively at just 10 cents per million tokens, offering a significant cost advantage over existing GPU options.
Powered by the Cerebras CS-3 system and the Wafer Scale Engine 3 (WSE-3) processor, the platform promises to maintain state-of-the-art accuracy without sacrificing speed, thanks to its 16-bit domain inference. The WSE-3 provides 7,000 times more memory bandwidth than the NVIDIA H100, addressing one of the core challenges of generative AI. Cerebras Inference is available across three pricing tiers—Free, Developer, and Enterprise—catering to different user needs, from basic access to custom enterprise solutions.
• Performance: 20x faster than GPU-based solutions, delivering 1,800 tokens per second on Llama 3.1 8B and 450 tokens per second on Llama 3.1 70B.
• Pricing: Starting at 10 cents per million tokens, significantly lower than GPU alternatives.
• Technology: Powered by the WSE-3 processor with 7,000x more memory bandwidth than NVIDIA H100.
• Availability: Offered in Free, Developer, and Enterprise tiers with varying levels of access and support.
“Speed and scale change everything,” said Kim Branson, SVP of AI/ML at GlaxoSmithKline, an early Cerebras customer.
“LiveKit is excited to partner with Cerebras to help developers build the next generation of multimodal AI applications. Combining Cerebras’ best-in-class compute and SoTA models with LiveKit’s global edge network, developers can now create voice and video-based AI experiences with ultra-low latency and more human-like characteristics,” said Russell D’sa, CEO and Co-Founder of LiveKit.
“For traditional search engines, we know that lower latencies drive higher user engagement and that instant results have changed the way people interact with search and with the internet. At Perplexity, we believe ultra-fast inference speeds like what Cerebras is demonstrating can have a similar unlock for user interaction with the future of search – intelligent answer engines,” said Denis Yarats, CTO and co-founder, Perplexity.