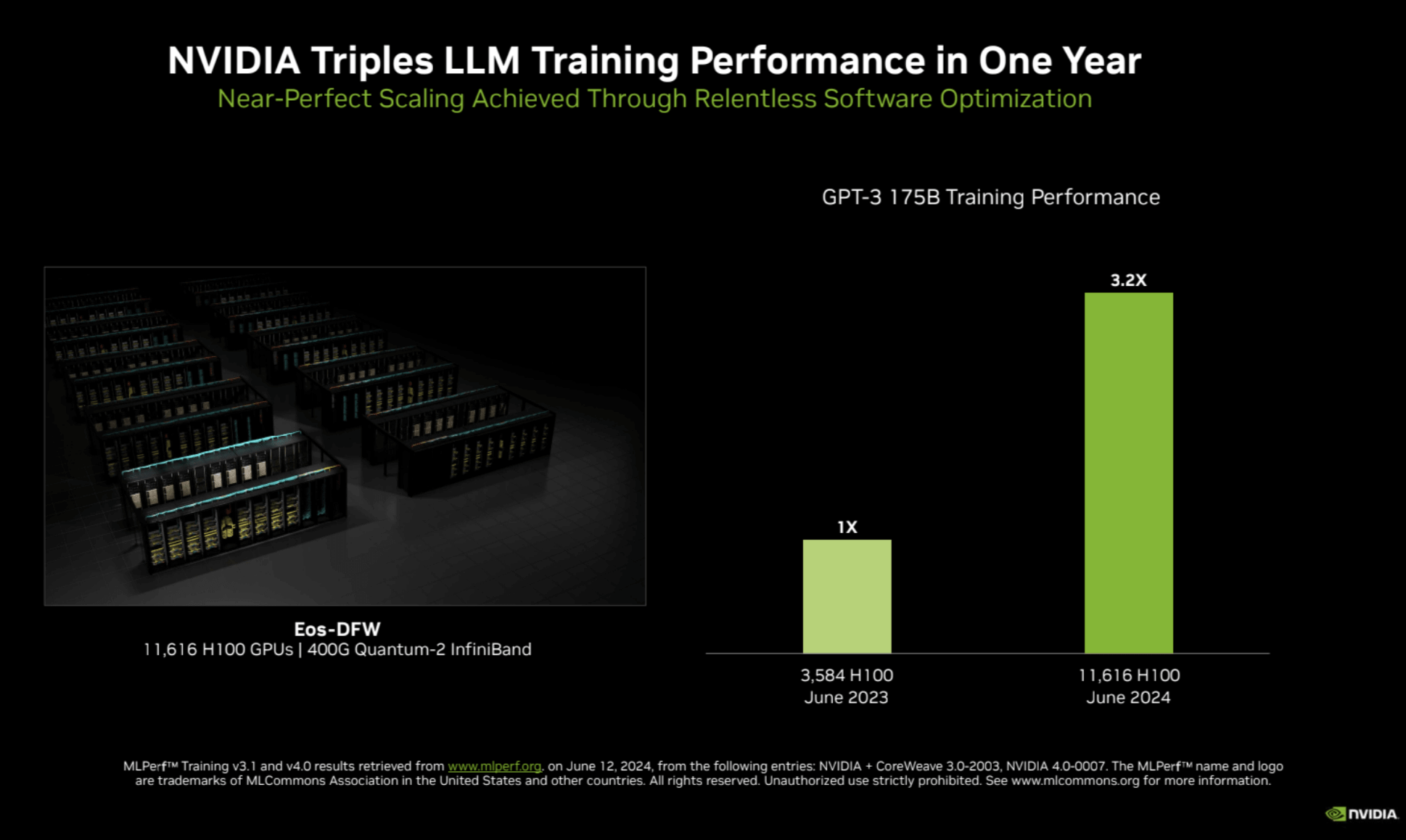
NVIDIA has achieved a remarkable milestone by more than tripling the performance on the large language model (LLM) benchmark, based on GPT-3 175B, compared to its record-setting submission from last year. This feat was accomplished using an AI supercomputer featuring 11,616 NVIDIA H100 Tensor Core GPUs, interconnected with NVIDIA Quantum-2 InfiniBand networking. The enhanced performance is attributed to the larger scale—more than triple the 3,584 H100 GPUs used previously—and extensive full-stack engineering improvements.
The scalability of the NVIDIA AI platform with InfiniBand networking, allows for significantly faster training of massive AI models like GPT-3 175B. This advancement translates into substantial business opportunities. For instance, NVIDIA’s recent earnings call highlighted how LLM service providers can achieve a sevenfold return on investment over four years by running the Llama 3 70B model on NVIDIA HGX H200 servers. This assumes a service charge of $0.60 per million tokens, with an HGX H200 server capable of processing 24,000 tokens per second.
The NVIDIA H200 Tensor Core GPU, building on the Hopper architecture, includes 141GB of HBM3 memory and over 40% more memory bandwidth than its predecessor, the H100. In its MLPerf Training debut, the H200 demonstrated up to a 47% performance increase compared to the H100. Additionally, software optimizations have made NVIDIA’s 512 H100 GPU configurations up to 27% faster than last year. This showcases the power of continuous software enhancements in boosting performance, even with the same hardware.
Some highlights:
- AI Supercomputer: 11,616 NVIDIA H100 Tensor Core GPUs connected with NVIDIA Quantum-2 InfiniBand.
- Performance Gains: Tripled LLM benchmark performance over last year’s submission.
- H200 GPU: Features 141GB HBM3 memory and 40% more memory bandwidth than H100.
- Software Optimizations: 512 H100 GPU configurations now 27% faster than a year ago.
- Scalability: GPU count increased from 3,584 to 11,616.
- LLM Service ROI: Potential sevenfold return on investment with Llama 3 70B on HGX H200 servers.
- Stable Diffusion and GNN Training: Up to 80% performance boost for Stable Diffusion v2 and significant gains in GNN training.
- Support: Participation from industry leaders like ASUS, Dell, HPE, Lenovo, and others in NVIDIA’s AI ecosystem.






